
一、前置知识
1.DDPM
- 论文:[2006.11239] Denoising Diffusion Probabilistic Models
- 代码:hojonathanho/diffusion: Denoising Diffusion Probabilistic Models
2.DDIM
3. LDM
- 论文:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
- 代码:CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
二、 简介
- 代码地址(v1):CompVis/stable-diffusion: A latent text-to-image diffusion model
- 代码地址(v2):Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
stable diffusion实际上是由LDM改进而来,LDM的主要工作是将端到端的像素级概率扩散过程放到潜空间进行。首先训练了一对VAE自分编码器,将图像映射到潜空间,再进行概率扩散,大大减少了对性能的要求。
[!note] Page 10686
We propose to circumvent this drawback by introducing an explicit separation of the compressive from the generative learning phase (see Fig. 2). To achieve this, we utilize an autoencoding model which learns a space that is perceptually equivalent to the image space, but offers significantly reduced computational complexity.
我们建议通过引入与生成学习阶段的压缩分离来规避这一缺点(见图2)。为了实现这一目标,我们利用了一个自动编码模型,该模型在感知上等同于图像空间,但具有大大降低的计算复杂性。
^95Z2VM4LaW8J36UR5p3
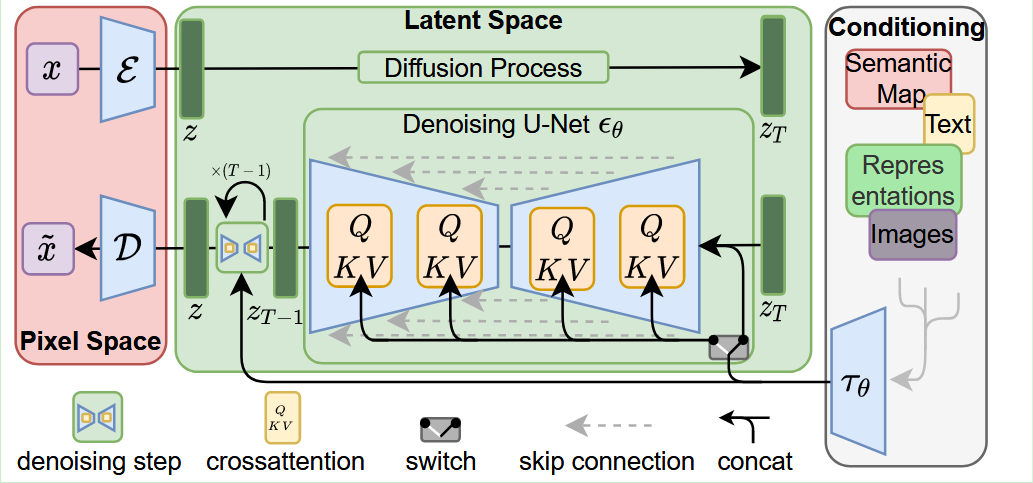
在stable diffusion v1的版本中,作者首先训练了一个 512 * 512 大小的生成器,提高了分辨率。文本编码器为CLIP ViT-L/14。后来Stability-AI和CompVis陆续发了几个版本,现在保留下来的v2版本又进行的加训,模型分辨率提高为 768 * 768 。
三、 代码结构
1. 文件结构
stablediffusion:.
├─assets
│ ├─stable-inpainting
│ └─stable-samples
│ ├─depth2img
│ ├─img2img
│ ├─stable-unclip
│ ├─txt2img
│ │ └─768
│ └─upscaling
├─checkpoints
├─configs
│ ├─karlo
│ └─stable-diffusion
│ └─intel
├─doc
├─ldm
│ ├─data
│ ├─models
│ │ └─diffusion
│ │ └─dpm_solver
│ └─modules
│ ├─diffusionmodules
│ ├─distributions
│ ├─encoders
│ ├─image_degradation
│ │ └─utils
│ ├─karlo
│ │ └─kakao
│ │ ├─models
│ │ └─modules
│ │ └─diffusion
│ └─midas
│ └─midas
└─scripts
├─gradio
├─streamlit
└─tests
- assets 主要是包含样例图和md的存图
- checkpoint 模型权重文件位置
- config 参数调整,这里主要是yaml文件
- doc 文档
- ldm 模型主结构
- scripts 模型使用脚本
2. 文件具体内容解析
- ldm/data/utils.py
文件中包含了一个AddMiDaS类,主要是处理MiDaS深度估计输入,将输入图像tensor格式为[-1,1]转换为numpy格式[0,1],方法主要是做线性映射。
- ldm/models/diffusion/dpm_solver/dpm_solver.py
文件中包含了一个NoiseScheduleVP类,主要定义噪声调度测量,该类中还描述了连续时间的DPM(Diffusion Probabilistic Model) 调用方式。
在同文件夹下的sampler.py中调用了该类,在第80行:
ns = NoiseScheduleVP('discrete', alphas_cumprod=self.alphas_cumprod)
其中:
- 在扩散模型的正向过程中,
alphas代表扩散过程的步长控制参数,其累积乘积alphas_cumprod用于控制噪声添加的强度。
文件中将主类写了一个包装函数model_wrapper用于参数传递,支持几种条件
文件中的主类为DPM_Solver,该模块主要是提高生成速度,在15-20步的去噪过程可以媲美传统方法(DDIM)100-250步的过程,类中定义了单步扩散,多步扩散,采样等方法,内容很多。
- ldm/models/diffusion/dpm_solver/sampler.py
本文件是核心采样器,主要是对DPM-Solver(Diffusion Probabilistic Model Solver) 算法进行包装,实现对扩散模型采样过程的加速和优化实现。
- 类
DPMSolverSampler中,传入参数为扩散模型和设备 register_buffer为注册缓存sample为采样主方法,传入参数后先检查条件conditioning与batch_size一致。
| 参数名 | 说明 |
|---|---|
| S | 采样步数 |
| shape | 生成图像形状(C,H,W) |
| conditioning | 条件输入(如文本Embedding) |
| x_T | 初始噪声图像 |
- 然后初始化采样图像张量,构建
NoiseScheduleVP调度器,构建模型包装器model_fn,创建DPM_Solver开始采样 - 返回生成的图像,形状为
(B,C,H,W)
- ldm/models/diffusion/ddim.py&ddpm.py
DDIM(Denoising Diffusion Implicit Models)是对扩散概率模型DDPM(Denoising Diffusion Probabilistic Models)的一种改进。核心总结为:
class DDIMSampler(object):
def __init__() # 初始化模型与设备
# 设置传入模型,设置原始训练步数,存储设备与调度策略
make_schedule() # 构建采样调度表
# 构建DDIM的时间步选择表,注册重要一些参数
sample() # 高层封装接口,调用 sampling 主过程
# 外部接口,设置调度表,构造随机初始噪声,调用ddim_sampling(),设置mask和x0
ddim_sampling() # 逐步执行 DDIM 推理
# 核心的去噪过程,循环所有采样时间步,反向执行DDIM采样
# 调用p_sample_ddim()单步处理
# 记录intermediates可视化
p_sample_ddim() # 单步采样过程(核心计算)
encode() # 编码阶段(图像 -> 潜空间)
stochastic_encode() # 随机编码图像为 latent(用于图像重构)
decode() # 解码阶段(潜空间 -> 图像)
- ldm/models/diffusion/plms.py
PLMS (Pseudo Linear Multistep)采样器的模块。PLMS 是对 DDIM 的改进,通过多步预测更精确地估计当前时刻的噪声,从而提升采样质量与速度。
class PLMSSampler(object):
def __init__(self, model, schedule="linear", device=torch.device("cuda"), **kwargs):
# 初始化函数,输入为model模型对象,schedule 时间步调度方式,device 设备
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
# 构造采集所需要的参数(如α,β)
def sample(self, S, batch_size, shape, conditioning=None, ...)
# 采样入口,流程:
# 1. 检查conditioning 与 batch_size 是否一致
# 2. 调用 make_schedule() 构造时间调度参数
# 3. 调用 plms_sampling() 执行实际采样过程
# 4. 返回最终图像和中间结果
def plms_sampling(self, cond, shape, ...)
# 使用 PLMS 方法进行图像采样:
# 1. 初始化噪声图像
# 2. 遍历时间步(倒序)
# 3. 每一步调用 p_sample_plms 去噪,并保存中间图像。
def p_sample_plms(self, x, c, t, index, ...)
# 该函数完成一小步的去噪采样
- ldm/models/diffusion/sampling_util.py
append_dims(x, target_dims)给张量 x 在最后面添加维度,直到它的维度数变成 target_dims。这是为了广播兼容性。在很多深度学习中,做乘除操作时要求维度对齐,通过扩展末尾维度可以让张量广播得更自然。
norm_thresholding(x0, value)对每个样本 x0[i] 的L2范数进行下限约束(clamp),如果范数太小(< value),就放大它使其不低于这个值。
spatial_norm_thresholding(x0, value)对每个像素位置 (b, h, w) 的通道向量 x0[b, :, h, w] 进行 L2 范数的约束。
- ldm/models/autoencoder.py
自分编码器,把图片编码至潜空间z进行加噪去噪。
def __init__(self, ddconfig, lossconfig, embed_dim, ckpt_path=None, ...)
| 组件 | 描述 |
|---|---|
Encoder,Decoder | 图像的编码器与解码器(定义在 ldm.modules.diffusionmodules.model) |
quant_conv, post_quant_conv | 中间变换:将 encoder 输出的 feature map 映射到高斯分布的均值/方差(2×embed_dim) |
DiagonalGaussianDistribution | 用于建模潜在空间分布 z∼N(μ,σ) |
def encode(self,x):
输入为image,输出为feature map。
评论